Trajectory Extraction
Maps contain important information to navigate and route vehicles. For autonomous vehicles this information about the surrounding has to be highly accurate and current to directly interpret and evaluate the surrounding, measured by sensors. The richer the information is, the better a vehicle can judge the situation, predict next steps and react. The surrounding of the vehicle can significantly influence the driving situation. Which conditions lead to unsafe driving behaviour is not always clear. Therefore, it is important to investigate how such situations can be reliably detected, and then search for their triggers. It is conceivable that such insecure situations (e.g. near-accidents, U-turns, avoiding obstacles) are reflected, for example, as anomalies in the movement trajectories of road users (Huang et al. 2014). Collecting real world traffic data in driving studies (e.g. (Barnard et al. 2016)) is very time consuming and expensive. On the other hand, a lot of roads or public areas are already monitored with video cameras. In addition, nowadays more and more of such video data is made publicly available over the internet so that the amount of free but low quality video data is increasing. This research will exploit the use of such kind of opportunistic VGI.
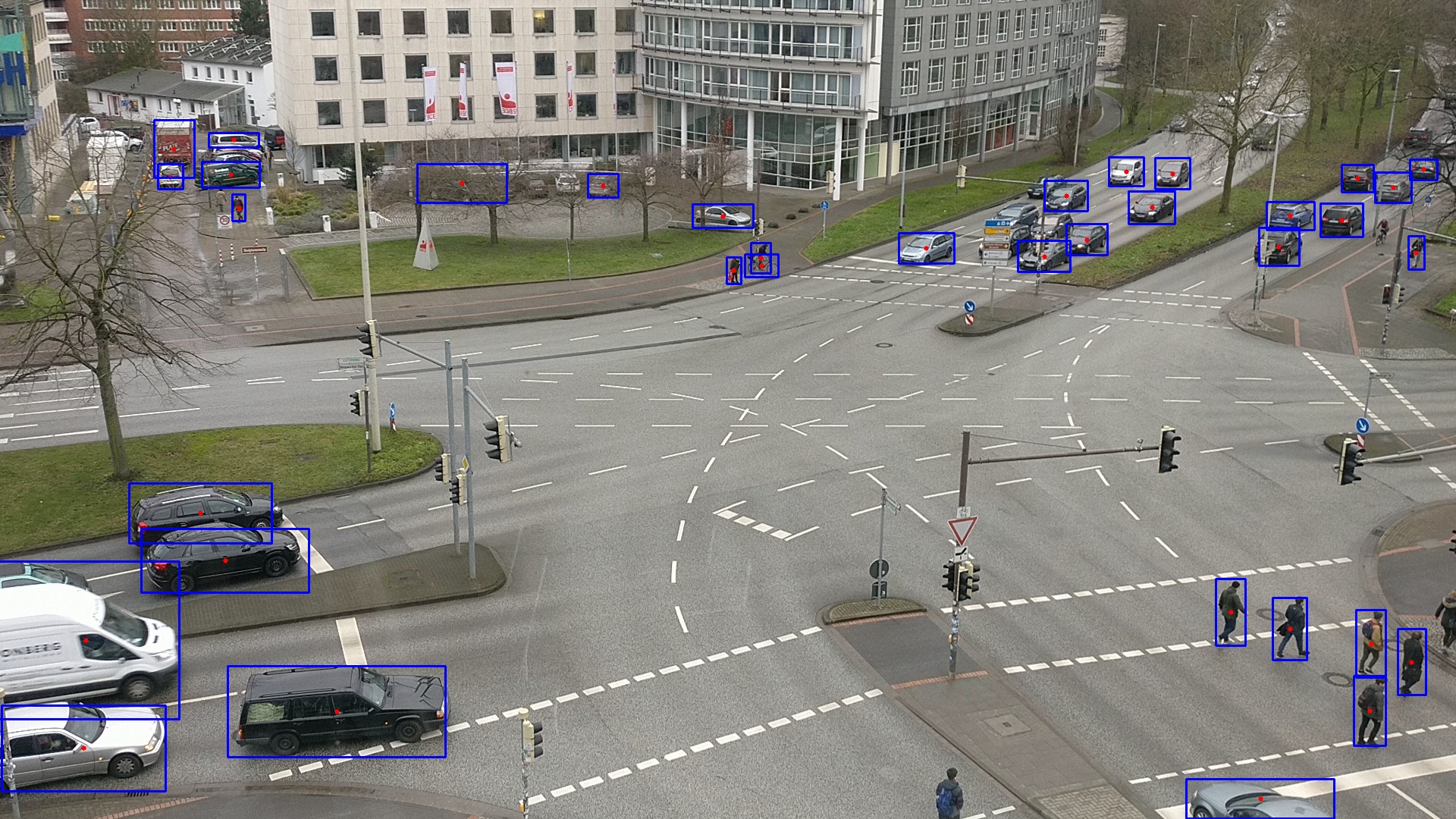
As basis for further research the aim of this work therefore is: (a) to introduce a real time processing pipeline to extract road user trajectories from surveillance video data, (b) especially evaluating the performance of a current state of the art real time detection neural network YOLO (Redmon et al. 2016) as well as a self-trained model for the specific context of road users and (c) to analyse the extracted road user trajectories for anomalies.
In general the surveillance camera pipeline works as follows: for each frame of the specified input video an object detection (using YOLO) will be performed, which returns a list of bounding boxes for all found objects in the scene. This list of found objects with their bounding boxes will then be used by a tracking algorithm, which returns a list of centroids for the tracked objects. In this architecture, the detector and trajectory calculation are separated, while still running in real time. The detector reviews raw video frames and outputs bounding boxes with classifying annotations. While the detector only looks at each frame once, the trajectory calculation uses information over a specified amount of frames to smooth out variance in the detection and do a plausibility check to prevent false tracking and reject false detections. Using a precomputed homography matrix for the concrete scene the camera coordinates are projected to a global coordinate system.
The biggest public available dataset in the domain of traffic monitoring seems to be the CityCam (Zhang et al. 2017a). It has been used for various forms of traffic analysis (Zhang et al. 2017b). However, - to our knowledge - there was no attempt made to gain additional metadata from the movement of road users. The dataset consists of 60 million frames from 212 webcams installed in key intersections of New York City. This poses various challenges, of changing locations, weather conditions, camera angles and low-resolution images. In addition, the CityCam data was enriched with other traffic monitoring data, such as the AAU RainSnow (Bahnsen et al. 2018) dataset. This provides an even bigger variance for evaluation.
To put this unique domain in perspective, the YOLO neural network was self-train with labeled images from the following common public object detection benchmark datasets: ImageNet (Deng et al. 2009), Pascal VOC (Everingham et al. 2010), COCO (Lin et al. 2014), Open Images (Krasin et al. 2017). The data was splitted into a training and validation set and - when necessary - transformed to match YOLOs data structure. Since the goal is to track road users and build a lightweight context specific neural network, the datasets were filtered in advance, so that the chosen images just showing at least one of the following classes: person, bicycle, motorbike, car, truck, bus. It was taken care about, that the number of images for each class is approximately equal distributed within the training and validation set.
The standard pretrained YOLO weights were compared with self-trained weights based on the following statistics: (a) the average intersection over union of the ground-truth bounding boxes and the detected bounding boxes over all frames for each class and (b) the detection runtime for all frames. The same datasets and statistics can be used to compare other detection methods to the one described in this paper and will be used in future work.
The trajectory analysis was performed on trajectories gathered from the introduced surveillance camera pipeline, which was applied to a video sequence of a webcam live stream of the Main Street in Canmore, Alberta, Canada, hosted on YouTube (Canmore Alberta 2019). After gathering, the raw road user trajectories are post processed and analysed. The main focus of the paper lies in the derivation of trajectories. However, first analysis on the trajectories will be conducted with respect to the detection of anomalies: (a) concerning traffic flow by searching for velocities deviating from typical daytime patterns and (b) concerning driving manoeuvres by searching for trajectories deviating from typical paths.
The source code and data will be made publicly available.
References
-
Bahnsen, C. H., Moeslund, T. B., 2018. Rain Removal in Traffic Surveillance: Does it Matter? In: IEEE Transactions on Intelligent Transportation Systems, pp. 1-18, doi.org/10.1109/TITS.2018.2872502
-
Barnard, Y., Utesch, F., Van Nes, N., Eenink, R., Baumann, M., 2016. The study design of UDRIVE: the naturalistic driving study across Europe for cars, trucks and scooters. In: European Transport Research Review, 8(14), doi.org/10.1007/s12544-016-0202-z
-
Canmore Alberta, 2019. Canmore Live Webcam “Main Street”. https://canmorealberta.com/webcams/main-street (04. February 2019)
-
Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., Fei-Fei, L., 2009. ImageNet: A Large-Scale Hierarchical Image Database. In: IEEE Computer Vision and Pattern Recognition, pp. 248-255, doi.org/10.1109/CVPR.2009.5206848
-
Everingham, M., Van Gool, L., Williams, C. K. I., Winn, J., Zisserman, A., 2010. The PASCAL Visual Object Classes (VOC) Challenge. In: International Journal of Computer Vision, 88(2), pp. 303-338, doi.org/10.1007/s11263-009-0275-4
-
Huang, H., Zhang, L., Sester, M., 2014. A Recursive Bayesian Filter for Anomalous Behavior Detection in Trajectory Data. In: Connecting a Digital Europe Through Location and Place. Lecture Notes in Geoinformation and Cartography, pp. 91-104, doi.org/10.1007/978-3-319-03611-3_6
-
Krasin, I., Duerig, T., Alldrin, N., Ferrari, V., Abu-El-Haija, S., Kuznetsova, A., Rom, H., Uijlings, J., Popov, S., Kamali, S., Malloci, M., Pont-Tuset, J., Veit, A., Belongie, S., Gomes, V., Gupta, A., Sun, C., Chechik, G., Cai, D., Feng, Z., Narayanan, D., Murphy, K., 2017. OpenImages: A public dataset for large-scale multi-label and multi-class image classification. https://storage.googleapis.com/openimages/web/index.html (04. February 2019)
-
Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár P., Zitnick, C. L., 2014. Microsoft COCO: Common Objects in Context. In: European Conference on Computer Vision, Lecture Notes in Computer Science, 8693, pp. 740-755, doi.org/10.1007/978-3-319-10602-1_48
-
Redmon, J., Divvala, S., Girshick, R., Farhadi, A., 2016. You Only Look Once: Unified, Real-Time Object Detection. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 779-788, doi.org/10.1109/CVPR.2016.91
-
Zhang, S., Wu, G., Costeira, J. P., Moura, J. M. F., 2017a. Understanding Traffic Density from Large-Scale Web Camera Data. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 4264-4273, doi.org/10.1109/CVPR.2017.454
-
Zhang, S., Wu, G., Costeira, J. P., Moura, J. M. F., 2017b. FCN-rLSTM: Deep Spatio-Temporal Neural Networks for Vehicle Counting in City Cameras. In: International Conference on Computer Vision, pp. 3687-3696, doi.org/10.1109/ICCV.2017.396
| Author: | M. Sc. Christian Koetsier |
| Last modified: | 2019-06-21 |